Le AI Data Wall (en français « Mur de données IA ») désigne la barrière (théorique) que rencontrent les modèles d’intelligence artificielle lorsqu’ils ne peuvent plus progresser en raison de l’épuisement des nouvelles données exploitables.
Étymologie
Ce concept combine les termes « AI » (Artificial Intelligence) et « Data Wall ». Il met en avant la contrainte structurelle imposée par la disponibilité limitée des données pour l’entraînement des nouveaux modèles d’IA.
Contexte et historique
L’évolution des modèles d’IA, notamment les grands modèles de langage (LLM), repose sur l’accès à de vastes quantités de données textuelles publiques.
Or, des études récentes estiment que ces modèles auront épuisé la totalité des données humaines disponibles entre 2026 et 2032, marquant ainsi un point critique connu sous le nom de AI Data Wall.
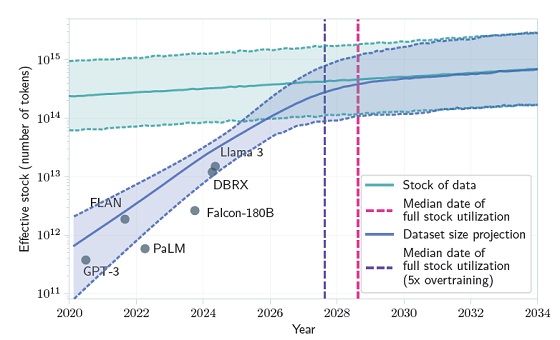
Le graphique ci-dessus compare le stock de données disponibles, exprimé en tokens et la progression de la consommation de données par les modèles d’IA jusqu’à leur épuisement supposé.
Causes du AI Data Wall
Le mur de données IA résulte de plusieurs facteurs :
- Épuisement des données publiques : Les IA ayant déjà absorbé la majorité des données accessibles sur Internet.
- Limites du paradigme « bigger is better » : Ajouter plus de données et de puissance de calcul n’entraînerait plus d’amélioration significative.
- Qualité des données : L’usage de données synthétiques (générées artificiellement par des algorithmes ou des modèles d’intelligence artificielle) pose des problèmes de biais, d’homogénéisation et de redondance. Ce qui impacte la pertinence des réponses de l’IA.
Variantes et concepts associés
- Plateau d’apprentissage : Phénomène où un modèle ne progresse plus malgré l’augmentation des données d’entraînement.
- Défi de la rareté des données (Data Scarcity Challenge) : Pénurie de données de qualité adaptées à l’entraînement de l’IA.
Solutions et alternatives
Face au AI Data Wall, plusieurs approches sont envisagées :
- Exploitation des données privées : Utilisation de données internes aux entreprises et organisations, non accessibles publiquement.
- Génération de données « synthétiques » : Création de nouveaux jeux de données, bien que cela puisse entraîner des risques comme indiqué précédemment.
- Fine-tuning : Personnalisation des modèles existants avec des données spécifiques à un domaine ou une organisation. Cette solution ne sera pas adaptée pour un modèle « public » en raison de la confidentialité des données.
- Apprentissage hybride : Combinaison de données humaines, synthétiques et d’apprentissage par transfert.
Ce qu’il faut retenir
Le AI Data Wall représente la barrière à laquelle sont confrontées les entreprises d’IA pour continuer à entrainer leurs modèles.
Cette théorie ne fait pas l’unanimité parmi les experts en IA.
Les chercheurs en IA explorent des alternatives : identifier de nouvelles sources de données, améliorer les algorithmes d’apprentissage ou optimiser les méthodes de génération de données synthétiques.