La vectorisation est un procédé qui convertit des données (textes, images, sons, etc.) en représentations numériques sous forme de vecteurs.
Dans le domaine de l’intelligence artificielle (IA), elle constitue un pilier essentiel de la plupart des algorithmes d’apprentissage automatique et d’apprentissage profond. Son objectif principal est de rendre les données compréhensibles et manipulables par des ordinateurs, tout en conservant leurs caractéristiques et leurs relations essentielles.
Étymologie
Le terme vectorisation puise ses racines dans le latin vector, qui signifie « porteur ».
En mathématiques, un vecteur est un objet qui comporte simultanément une direction et une magnitude. Historiquement, le mot « vectorisation » était surtout associé à l’impression ou au graphisme, où il décrit la conversion d’images bitmap en images vectorielles (reposant sur des formes géométriques).
En intelligence artificielle, le terme a évolué pour désigner la transformation d’ensembles de données complexes en listes de nombres.
Contexte et historique
- Débuts de l’informatique (années 1950-1970) : Les premiers algorithmes d’apprentissage automatique étaient limités par la capacité de traitement et la représentation des données.
- Évolution dans les années 1980-1990 : Les premières techniques de vectorisation pour le traitement du langage naturel émergent, notamment le Bag of Words.
- Années 2000-2010 : Apparition de méthodes plus avancées telles que les word embeddings (Word2Vec, GloVe), permettant d’obtenir des représentations sémantiques des mots.
- Ère du Deep Learning (années 2010 à aujourd’hui) : La popularité croissante des réseaux neuronaux profonds s’accompagne de la nécessité de manipuler des représentations vectorielles de grande dimension.
Ce progrès s’explique par la puissance de calcul accrue (CPUs, GPUs, TPUs) et la disponibilité de volumes de données massifs. La vectorisation joue un rôle crucial dans cette évolution, car elle permet de rendre les données « calculables » à grande échelle.
Explication détaillée
La vectorisation, en IA, regroupe un ensemble de techniques pour transformer des données brutes en représentations numériques cohérentes.
Ces représentations sont généralement des vecteurs (tableaux de nombres) que l’on peut manipuler pour mesurer la proximité et la similarité.
Cette technique a permis l’émergence des modèles d’IA comme ChatGPT Vision ou Nano Banana (Gemini).
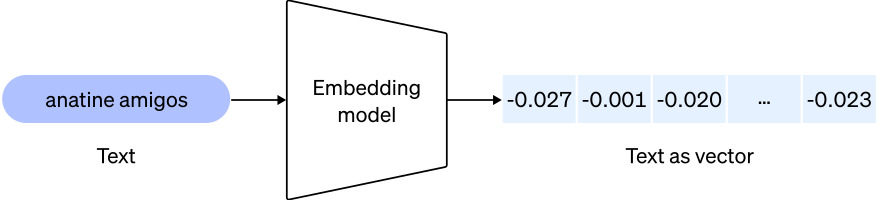
Représentation d’une vectorisation. Source : developers.google.com
Techniques de vectorisation
- Vectorisation de texte
- Bag of Words : Conversion du texte en un vecteur dans lequel chaque dimension correspond à l’occurrence d’un mot.
- TF-IDF : Pondération tenant compte de la fréquence du mot dans un document et de sa rareté dans la collection. C’est une technique utilisée notamment dans le référencement naturel (SEO).
- Word Embeddings : Méthodes comme Word2Vec, GloVe ou FastText, qui produisent des vecteurs capturant les relations sémantiques.
- Vectorisation d’images
- Extraction de caractéristiques via les réseaux neuronaux convolutionnels (CNN).
- Utilisation de descripteurs de formes, de couleurs ou de textures pour représenter une image.
- Vectorisation d’audio ou de signaux
- Extraction de caractéristiques spectrales (MFCC pour la voix).
- Utilisation de réseaux neuronaux pour modéliser les séquences temporelles.
- Vectorisation de graphes
- Conversion de nœuds et d’arêtes en vecteurs (Graph Embeddings).
- Utilisation de Graph Neural Networks pour saisir la structure du graphe.
Une fois les données vectorisées, on peut évaluer la distance ou la similarité entre deux entités (euclidienne, cosinus, etc.) afin de réaliser diverses tâches comme le clustering, la classification ou la recherche d’information.
Variantes du concept
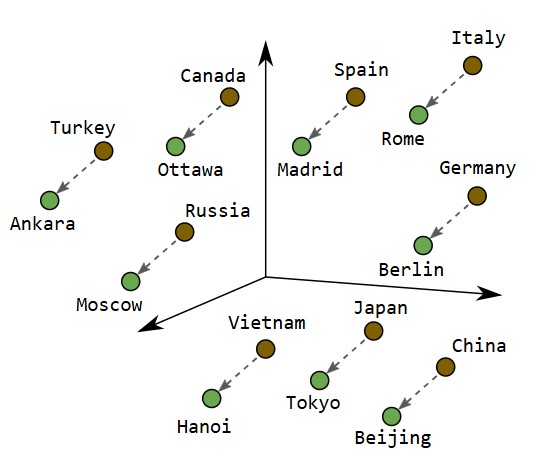
- Embeddings : Représentations vectorielles avancées. Cette technique est utilisée par les grands modèles de langage tels que ChatGPT.
Voici une illustration issue de OpenAI :
- One-Hot Encoding : Transformation simple convertissant une catégorie en un vecteur binaire.
- Hashing Trick : Méthode rapide mappant les mots à des indices via une fonction de hachage.
- Encodage catégoriel : Convertit des variables catégorielles (ex. pays, ville) en vecteurs numériques.
Les frameworks tels que TensorFlow ou PyTorch proposent des fonctions prêtes à l’emploi pour vectoriser différents types de données, facilitant ainsi l’implémentation de modèles d’IA.
Applications pratiques
- Moteurs de recherche
- Recherche par similarité sémantique : trouver des documents, images ou vidéos correspondant à une requête donnée. C’est typiquement ce que fait Google.
- Systèmes de recommandation : suggestion de produits ou de contenus basés sur la proximité vectorielle.
- Traitement du langage naturel (TLN)
- Analyse de sentiments, résumé de texte, traduction automatique, etc.
- Vision par ordinateur
- Reconnaissance d’images, détection d’objets. C’est l’un des mécanismes utilisés pour les voitures autonomes.
- Classification et indexation d’images.
- Systèmes de recommandation
- Personnalisation sur les plateformes de streaming vidéo, par exemple.
- Analyse prédictive et Big Data
- Détection d’anomalies : permettant par exemple, de prévenir des fraudes.
- Clustering pour segmenter des populations ou des clients.
Dans chaque cas, la vectorisation est le point de départ indispensable pour faire fonctionner les algorithmes d’IA.
Avantages et limites
Avantages de la vectorisation
- Efficacité de calcul : Les opérations sur les vecteurs sont très rapides, en particulier sur GPU.
- Flexibilité : Les mêmes techniques de vectorisation peuvent être appliquées à des types de données variés (texte, image, audio, etc.).
- Qualité des représentations : Les méthodes modernes (embeddings) capturent des relations complexes au sein des données.
Limites de la vectorisation
- Dimensionnalité : Des vecteurs trop grands peuvent générer d’importants coûts de calcul et de stockage.
- Besoin de données massives : L’apprentissage de vecteurs de haute qualité requiert de vastes jeux de données.
- Biais : Les biais présents dans les données initiales se retrouvent dans les représentations vectorielles.
Ce qu’il faut retenir
La vectorisation est un axe central en intelligence artificielle. Elle consiste à convertir n’importe quel type de données — textuelles, visuelles, sonores — en vecteurs numériques aisément manipulables.
Sans cette étape, la plupart des algorithmes d’IA ne pourraient ni comparer ni classifier efficacement les données.
Points clés
- Les techniques de vectorisation et leurs performances influent directement sur la qualité des rendus des modèles.
- L’apprentissage profond (Deep Learning) s’appuie fortement sur les représentations vectorielles pour traiter des tâches complexes. C’est typiquement le cas pour les modèles d’IA les plus connus tels que ChatGPT ou Gemini.
- Les biais présents dans les données se répercutent dans les vecteurs et nécessitent une attention particulière.
Les progrès dans ce domaine cherchent à atténuer cette limitation liée au volume de données requises pour les calculs, appelée aussi « Mur de données ».