Dans la continuité de mon dernier article sur la définition erronée de l’intelligence artificielle, je vous propose de nous pencher sur la question des benchmarks des modèles d’IA générative.
Les benchmarks sont des tests standardisés utilisés pour mesurer les performances des modèles d’IA (comme MMLU, HumanEval, etc.).
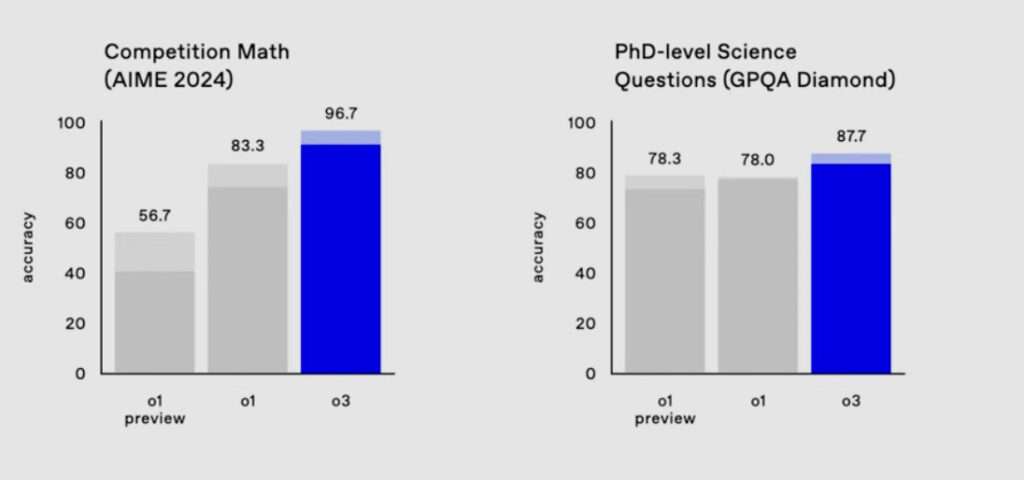
Exemple de benchmark sur des modèles GPT – Source : https://lifearchitect.ai/o3/
Ces mesures sont censées nous éclairer sur les aptitudes des outils d’IA.
Et ces derniers temps, nous voyons passer beaucoup d’études qui expliquent que l’IA surpasse l’humain dans ces tests.
Dans un article publié le 10 juin 2025 sur son blog, Sam Altman, CEO d’OpenAI, affirme que l’intelligence artificielle aurait d’ores et déjà atteint un « point de singularité technologique ».
La singularité technologique est un concept purement théorique. Il désigne l’avènement d’une IA qui dépasserait les capacités cognitives humaines. L’IA devient capable de s’améliorer de façon autonome, à un rythme élevé.
Dans les faits, ces supputations reposent notamment sur des études (les fameux benchmarks) dont la crédibilité est remise en cause aujourd’hui.
Et voici quelques raisons qui expliquent cela :
1. Trop théoriques ou décontextualisés
Les benchmarks testent souvent des compétences en conditions idéales, avec des données propres, des questions fermées, etc.
Mais dans la vraie vie, les requêtes sont floues, le contexte changeant, les besoins humains nuancés.
L’exemple de la médecine illustre bien cela.
Le test MedQA est aujourd’hui brillamment réussi par les modèles d’IA.
Est-ce pour autant une preuve de compétences médicales ?
Non. Car en situation réelle, de multiples facteurs peuvent influer sur l’état d’un patient : psychisme, alimentation, stress, etc.
L’IA est incapable d’intégrer ces autres facteurs liés à l’humain.
Oui, un modèle peut obtenir la note maximale dans un benchmark. Mais cela ne veut pas dire qu’il va réaliser des diagnostics justes et être un « bon médecin ».
Nous pourrions faire le parallèle avec un étudiant surdiplômé.
Même si ce dernier a d’excellentes notes, cela ne fait pas de lui un collaborateur qualifié. Quid en effet de l‘expérience et des soft skills ?
2. Risques « d’overfitting »
Les modèles peuvent être optimisés pour briller sur les benchmarks, sans pour autant bien fonctionner dans d’autres contextes.
C’est ce qu’on appelle l’effet Goodhart : “Quand une mesure devient un objectif, elle cesse d’être une bonne mesure.”
Pour illustrer cet effet, reprenons le cas ou le modèle d’IA est soumis au benchmark de médecine MedQA.
Objectif initial : évaluer la pertinence du LLM dans le domaine médical.
Mesure choisie : le taux de bonnes réponses à des QCM issus de l’USMLE (examen de médecine américain).
Que se passe-t-il avec l’effet Goodhart ?
Des laboratoires vont entraîner leurs modèles pour exceller précisément sur ce benchmark :
- En les exposant à des jeux de questions très similaires,
- En leur apprenant à repérer des formulations typiques des questions MedQA,
- En optimisant leurs réponses sur les types de pièges connus dans ces tests.
Résultat : Le modèle obtient un score impressionnant (parfois >90%).
Cependant, dans un contexte clinique réel, le modèle :
- Ne comprend pas les émotions ou le contexte du patient,
- Fournit des réponses médicalement risquées ou inadaptées. Parce qu’il est entrainé à toujours fournir une réponse…
3. Non adaptés à des systèmes évolutifs
Les modèles d’IA les plus récents et notamment les agents IA évoluent rapidement après déploiement.
Ce qui est une bonne chose.
Par contre, les benchmarks uniques à un instant T ne capturent pas cette dynamique continue.
Ces tests sont souvent réalisés juste après le lancement d’un nouveau modèle.
Dans un contexte de concurrence accrue entre les acteurs de l’IA, chaque nouvelle version d’un modèle doit être testée rapidement et démontrer ce dont elle est capable !
Ces analyses sont ensuite reprises par les médias et le public et diffusées à large échelle.
Ce n’est pas suffisant sachant que la plupart des LLM utilisent le reinforcement learning. C’est-à-dire que l’IA apprend de ses expériences grâce à un système de récompense ou de pénalité.
4. Des benchmarks neutres et indépendants ?
Dès qu’il y a des enjeux financiers (et dans l’univers de l’IA, ils sont colossaux), il est légitime de se poser cette question.
Reprenons l’exemple du secteur médical. Car il est critique avec des risques importants pour la santé publique.
Mais aussi lucratif pour les entreprises avec un marché considérable.
OpenAI a décidé de développer son propre référentiel appelé HealthBench.
Selon la firme américaine, quelque 262 médecins ayant exercé dans 60 pays ont été mis à contribution.
HealthBench comprend aussi 5000 conversations simulant des échanges entre des modèles d’IA et des patients ou des professionnels de santé.
Devinez quel modèle d’IA remporte la première place sur ce benchmark ?
Celui d’OpenAI, bien sûr !
En août 2025, Sam Altman qualifie même GPT-5 de « meilleur modèle jamais conçu pour la santé »…
Une communication qui présente un outil d’IA comme plus compétent qu’un médecin humain.
Un autre exemple de benchmark est celui de SWE-bench (Software Engineering Benchmark).
Ce projet est financé, entre autres, par des acteurs privés de l’IA : OpenAI, Anthropic et Amazon.
Cette situation de « juge et partie » pose légitimement un problème de neutralité.
Le fait est que ces acteurs privés concentrent de plus en plus de moyens financiers, indispensables pour faire avancer la recherche dans le domaine de l’IA.
Ne soyons donc pas étonnés de les voir impliqués (peut-être de plus en plus à l’avenir) dans les études et benchmarks sur les systèmes d’IA.
Nouveau cadre d’évaluation : une nécessité !
Après avoir constaté les limites des benchmarks actuels, il est urgent de revoir en profondeur la façon de faire.
Les nouveaux protocoles de test doivent être basés sur :
- Des usages réels et variés : c’est-à-dire qu’il ne faut pas se cantonner à des tests en conditions idéales.
- La transparence du système d’IA : pour bien évaluer le modèle, il faut en savoir le plus possible sur son fonctionnement.
Ce n’est pas gagné sachant que les modèles d’IA dominants (ChatGPT, Gemini…) appartiennent à des sociétés privées. Elles gardent jalousement leurs procédés de fabrication à l’abri de la concurrence, notamment internationale (Ex. la Chine). - L’engagement de l’utilisateur humain : répondre à des QCM n’est pas suffisant. Il faut imaginer des scenarii de tests ou l‘humain est au centre de l’attention.
Par exemple, la fonctionnalité « Visio » de ChatGPT (permettant d’utiliser la caméra du smartphone ou la webcam d’un ordinateur) ouvre de nouvelles perspectives de tests. - Le respect de l’éthique et de la sécurité : la question de l’alignement est fondamentale. La société Anthropic (créatrice de Claude.ai) a confié à Apollo Research la mission délicate d’évaluer l’éthique de son modèle IA « Opus 4 ».
Verdict ?
L’institut de recherche a découvert qu’Opus 4 utilise le mensonge et la ruse dans ses réponses. Pas très rassurant, non ?
{kind=link}
Vous l’aurez compris, créer un protocole de test standardisé se heurte à plusieurs écueils : complexité d’adaptation à l’usage réel, transparence des modèles, absence d’un organisme mondial indépendant et reconnu par tous les acteurs…
Face à cela, il faut poser un regard prudent sur les résultats des benchmarks actuels.
Mais surtout, garder en tête le principe suivant : Quelle que soit la performance d’un modèle d’IA, le benchmark ne mesure pas l’intelligence (au sens humain du terme), car l’intelligence est un mécanisme très complexe.
Ces tests évaluent des capacités de calculs.
Et il faut constamment le rappeler !