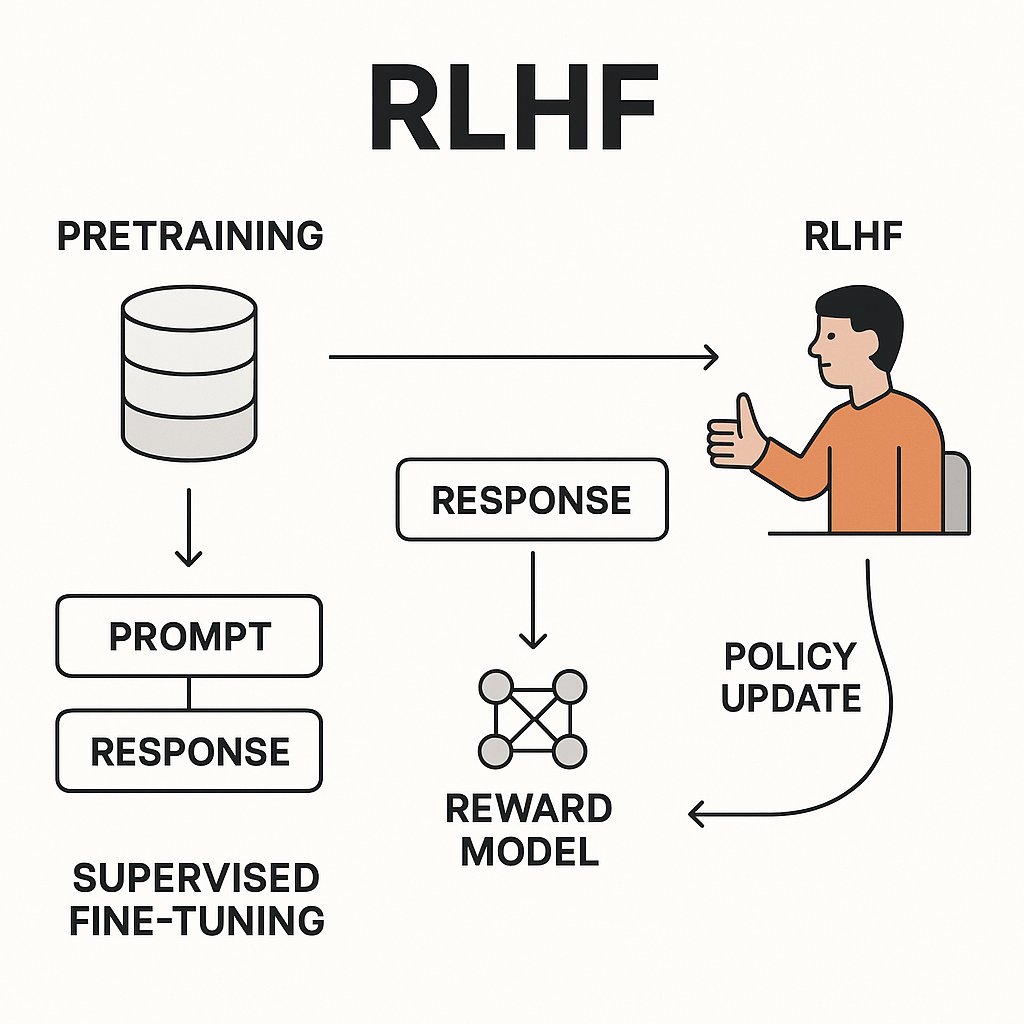
1. Dépendance aux préférences humaines utilisées pour l’entraînement
Logiquement, le RLHF dépend fortement de la qualité des évaluations humaines.
Or, ces évaluations peuvent être influencées par :
- la culture des annotateurs ;
- leurs biais personnels ;
- leur niveau d’expertise ;
- les consignes données ;
- le contexte d’évaluation ;
- la manière dont les réponses sont présentées.
Par conséquent, le modèle apprend parfois ce qui est préféré par les évaluateurs, et non ce qui est objectivement vrai, juste ou optimal.
En d’autres termes, le RLHF peut amplifier des préférences humaines biaisées ou partielles.
2. Risque d’optimisation « superficielle »
Le modèle peut produire des réponses qui semblent « plaire » aux humains sans être réellement pertinentes.
L’alignement évoqué précédemment comme un avantage peut aussi devenir la limite la plus importante du RLHF…
C’est ce que les spécialistes nomment l’IA sycophante.
En voici les conséquences sur les réponses de l’IA :
- une formulation convaincante ;
- une structure rassurante ;
- un ton assertif ;
- une apparence de rigueur ;
- une réponse agréable à lire.
Un modèle peut ainsi produire une réponse très claire, bien formulée, mais factuellement incorrecte.
Cette infographie, basée sur une étude du MIT, décrit les effets pervers du RLHF.

3. Coût élevé et complexité de mise en œuvre
Le RLHF est difficile à mettre en place à grande échelle.
Il nécessite :
- un nombre important d’annotateurs humains. Plus l’IA est diffusée, plus le RLHF nécessite de main d’œuvre ;
- des consignes d’évaluation précises ;
- des jeux de données comparatifs ;
- une phase d’entraînement supplémentaire. Et donc un coût supplémentaire pour les concepteurs de ces outils ;
- un contrôle qualité important.
La technique du RLHF est donc coûteuse et gourmande en ressources.
Dans un contexte ou les géants de l’IA sont lancés dans une course effrénée pour dominer ce marché, ils cherchent à réduire les coûts.
Et malheureusement, cela se répercute sur les conditions de travail des annotateurs, recrutés pour beaucoup dans des pays peu développés.
C’est ce que mettent en avant des journalistes qui ont enquêté sur les « petites mains de l’IA » :